|
|

|
Processed through Paypal No account required. |
Buy our over-priced crap to help pay the bills.








|
|
|
Processed through Paypal No account required. |
| File - Download DocFetcher v1.1.27 | ||||||||
| Description | ||||||||
|
A plea... Deanna and I have been running this site since 2008 and lately we're seeing a big increase in users (and cost) but a decline in percentage of users who donate. Our ad-free and junkware-free download site only works if everyone chips in to offset the revenue that ads on other sites bring in. Please donate at the bottom of the page. Every little bit helps. Thank you so much. Sincerely, your Older Geeks: Randy and Deanna Always scroll to the bottom of the page for the main download link. We don't believe in fake/misleading download buttons and tricks. The link is always in the same place. DocFetcher v1.1.27 👉 Fast, open-source desktop search tool for finding text inside documents. DocFetcher is an open-source desktop search application that allows you to quickly search the contents of documents on your computer. Instead of only searching filenames, DocFetcher indexes the full text of supported file types, making it easy to locate information buried deep inside PDFs, Word files, spreadsheets, and more. Once indexed, searches are nearly instantaneous and results are displayed with highlighted matches for quick context. 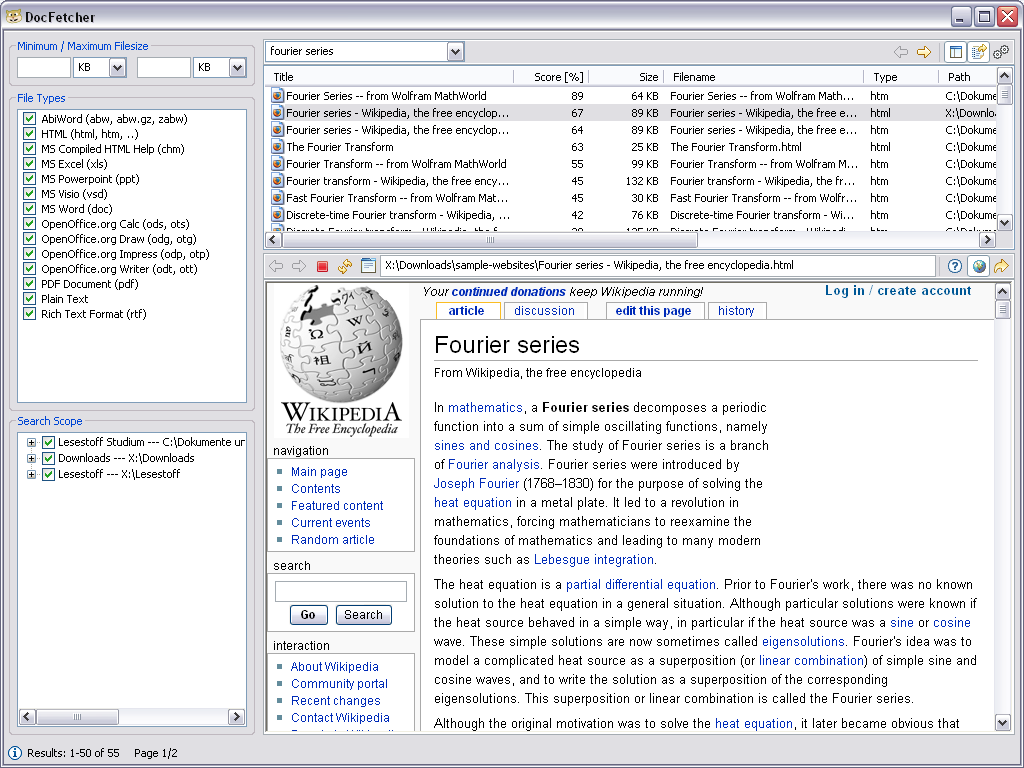 Basic Usage The screenshot below shows the main user interface. Queries are entered in the text field at (1). The search results are displayed in the result pane at (2). The preview pane at (3) shows a text-only preview of the file currently selected in the result pane. All matches in the file are highlighted in yellow. You can filter the results by minimum and/or maximum filesize (4), by file type (5) and by location (6). The buttons at (7) are used for opening the manual, opening the preferences and minimizing the program into the system tray, respectively. 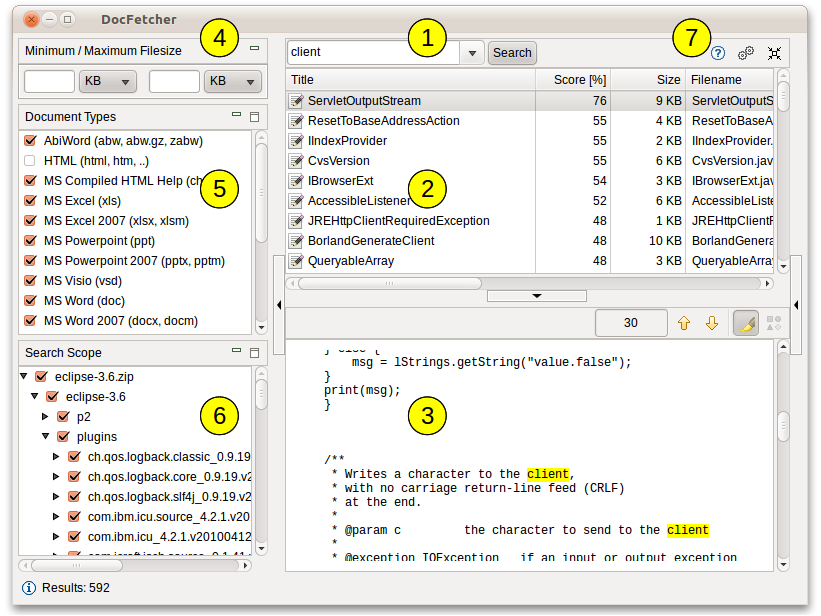 DocFetcher requires that you create so-called indexes for the folders you want to search in. What indexing is and how it works is explained in more detail below. In a nutshell, an index allows DocFetcher to find out very quickly (in the order of milliseconds) which files contain a particular set of words, thereby vastly speeding up searches. The following screenshot shows DocFetcher's dialog for creating new indexes: 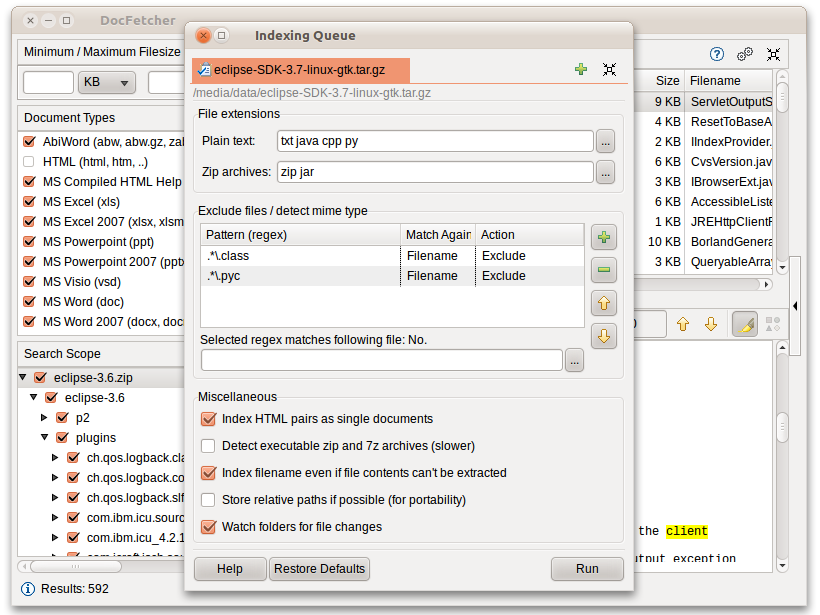 Clicking on the "Run" button on the bottom right of this dialog starts the indexing. The indexing process can take a while, depending on the number and sizes of the files to be indexed. A good rule of thumb is 200 files per minute. While creating an index takes time, it has to be done only once per folder. Also, updating an index after the folder's contents have changed is much faster than creating it — it usually takes only a couple of seconds. Notable Features • A portable version: There is a portable version of DocFetcher that runs on Windows, Linux and OS X. How this is useful is described in more detail further down this page. • 64-bit support: Both 32-bit and 64-bit operating systems are supported. • Unicode support: DocFetcher comes with rock-solid Unicode support for all major formats, including Microsoft Office, OpenOffice.org, PDF, HTML, RTF and plain text files. • Archive support: DocFetcher supports the following archive formats: zip, 7z, rar, and the whole tar.* family. The file extensions for zip archives can be customized, allowing you to add more zip-based archive formats as needed. Also, DocFetcher can handle an unlimited nesting of archives (e.g. a zip archive containing a 7z archive containing a rar archive... and so on). • Search in source code files: The file extensions by which DocFetcher recognizes plain text files can be customized, so you can use DocFetcher for searching in any kind of source code and other text-based file formats. (This works quite well in combination with the customizable zip extensions, e.g. for searching in Java source code inside Jar files.) • Outlook PST files: DocFetcher allows searching for Outlook emails, which Microsoft Outlook typically stores in PST files. • Detection of HTML pairs: By default, DocFetcher detects pairs of HTML files (e.g. a file named "foo.html" and a folder named "foo_files"), and treats the pair as a single document. This feature may seem rather useless at first, but it turned out that this dramatically increases the quality of the search results when you're dealing with HTML files, since all the "clutter" inside the HTML folders disappears from the results. • Regex-based exclusion of files from indexing: You can use regular expressions to exclude certain files from indexing. For example, to exclude Microsoft Excel files, you can use a regular expression like this: .*\.xls • Mime-type detection: You can use regular expressions to turn on "mime-type detection" for certain files, meaning that DocFetcher will try to detect their actual file types not just by looking at the filename, but also by peeking into the file contents. This comes in handy for files that have the wrong file extension. • Powerful query syntax: In addition to basic constructs like OR, AND and NOT DocFetcher also supports, among other things: Wildcards, phrase search, fuzzy search ("find words that are similar to..."), proximity search ("these two words should be at most 10 words away from each other"), boosting ("increase the score of documents containing...") Supported Document Formats • Microsoft Office (doc, xls, ppt) • Microsoft Office 2007 and newer (docx, xlsx, pptx, docm, xlsm, pptm) • Microsoft Outlook (pst) • OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp) • Portable Document Format (pdf) • EPUB (epub) • HTML (html, xhtml, ...) • TXT and other plain text formats (customizable) • Rich Text Format (rtf) • AbiWord (abw, abw.gz, zabw) • Microsoft Compiled HTML Help (chm) • MP3 Metadata (mp3) • FLAC Metadata (flac) • JPEG Exif Metadata (jpg, jpeg) • Microsoft Visio (vsd) • Scalable Vector Graphics (svg) Comparison To Other Desktop Search Applications In comparison to other desktop search applications, here's where DocFetcher stands out: • Crap-free: We strive to keep DocFetcher's user interface clutter- and crap-free. No advertisement or "would you like to register...?" popups. No useless stuff is installed in your web browser, registry or anywhere else in your system. • Privacy: DocFetcher does not collect your private data. Ever. Anyone in doubt about this can check the publicly accessible source code. • Free forever: Since DocFetcher is Open Source, you don't have to worry about the program ever becoming obsolete and unsupported, because the source code will always be there for the taking. Speaking of support, have you gotten the news that Google Desktop, one of DocFetcher's major commercial competitors, was discontinued in 2011? Well... • Cross-platform: Unlike many of its competitors, DocFetcher does not only run on Windows, but also on Linux and OS X. Thus, if you ever feel like moving away from your Windows box and on to Linux or OS X, DocFetcher will be waiting for you on the other side. • Portable: One of DocFetcher's greatest strengths is its portability. Basically, with DocFetcher you can build up a complete, fully searchable document repository, and carry it around on your USB drive. More on that in the next section. • Indexing only what you need: Among DocFetcher's commercial competitors, there seems to be a tendency to nudge users towards indexing the entire hard drive — perhaps in an attempt to take away as many decisions as possible from supposedly "dumb" users, or worse, in an attempt to harvest more user data. In practice though, it seems safe to assume that most people don't want to have their entire hard drive indexed: Not only is this a waste of indexing time and disk space, but it also clutters the search results with unwanted files. Hence, DocFetcher indexes only the folders you explicitly want to be indexed, and on top of that you're provided with a multitude of filtering options. Portable Document Repositories One of DocFetcher's outstanding features is that it is available as a portable version which allows you to create a portable document repository — a fully indexed and fully searchable repository of all your important documents that you can freely move around. • Usage examples: There are all kinds of things you can do with such a repository: You can carry it with you on a USB drive, burn it onto a CD-ROM for archiving purposes, put it in an encrypted volume (recommended: TrueCrypt), synchronize it between multiple computers via a cloud storage service like DropBox, etc. Better yet, since DocFetcher is Open Source, you can even redistribute your repository: Upload it and share it with the rest of the world if you want. • Java: Performance and portability: One aspect some people might take issue with is that DocFetcher was written in Java, which has a reputation of being "slow". This was indeed true ten years ago, but since then Java's performance has seen much improvement, according to Wikipedia. Anyways, the great thing about being written in Java is that the very same portable DocFetcher package can be run on Windows, Linux and OS X — many other programs require using separate bundles for each platform. As a result, you can, for example, put your portable document repository on a USB drive and then access it from any of these operating systems, provided that a Java runtime is installed. How Indexing Works This section tries to give a basic understanding of what indexing is and how it works. • The naive approach to file search: The most basic approach to file search is to simply visit every file in a certain location one-by-one whenever a search is performed. This works well enough for filename-only search, because analyzing filenames is very fast. However, it wouldn't work so well if you wanted to search the contents of files, since full text extraction is a much more expensive operation than filename analysis. • Index-based search: That's why DocFetcher, being a content searcher, takes an approach known as indexing: The basic idea is that most of the files people need to search in (like, more than 95%) are modified very infrequently or not at all. So, rather than doing full text extraction on every file on every search, it is far more efficient to perform text extraction on all files just once, and to create a so-called index from all the extracted text. This index is kind of like a dictionary that allows quickly looking up files by the words they contain. • Telephone book analogy: As an analogy, consider how much more efficient it is to look up someone's phone number in a telephone book (the "index") instead of calling every possible phone number just to find out whether the person on the other end is the one you're looking for. — Calling someone over the phone and extracing text from a file can both be considered "expensive operations". Also, the fact that people don't change their phone numbers very frequently is analogous to the fact that most files on a computer are rarely if ever modified. • Index updates: Of course, an index only reflects the state of the indexed files when it was created, not necessarily the latest state of the files. Thus, if the index isn't kept up-to-date, you could get outdated search results, much in the same way a telephone book can become out of date. However, this shouldn't be much of a problem if we can assume that most of the files are rarely modified. Additionally, DocFetcher is capable of automatically updating its indexes: (1) When it's running, it detects changed files and updates its indexes accordingly. (2) When it isn't running, a small daemon in the background will detect changes and keep a list of indexes to be updated; DocFetcher will then update those indexes the next time it is started. And don't you worry about the daemon: It has really low CPU usage and memory footprint, since it does nothing except noting which folders have changed, and leaves the more expensive index updates to DocFetcher. 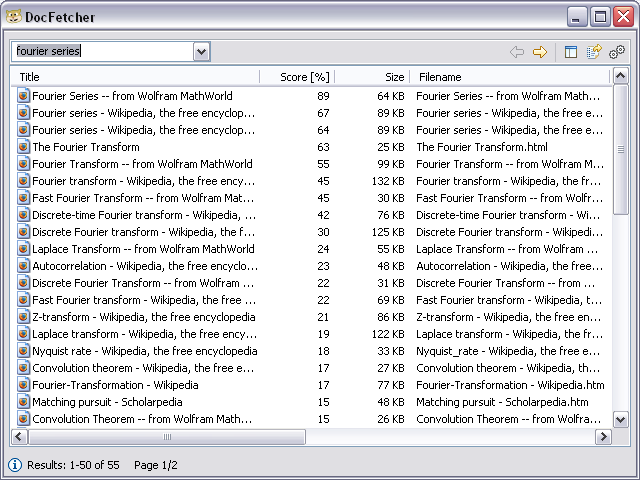 Supported operating systems: • Windows 7, Windows 8, Windows 10, Windows 11 • macOS 10.13 or higher • Linux Supported languages: English, German, French, Spanish, Italian, Portuguese, Dutch, Polish, Russian, Chinese, Japanese, Korean This download is for the Windows portable version (very bottom of page). All other download assets are below: Other Windows: DocFetcher-1.1.27-Windows-64bit-Setup.exe MacOS: DocFetcher-1.1.27-macOS-64bit-NonPortable.dmg DocFetcher-1.1.27-macOS-64bit-Portable.dmg Linux: DocFetcher-1.1.27-Linux-64bit-NonPortable.zip DocFetcher-1.1.27-Linux-64bit-Portable.zip Click here to visit the author's website. Continue below for the main download link. |
||||||||
| Downloads | Views | Developer | Last Update | Version | Size | Type | Rank | |
| 5,690 | 20,118 | DocFetcher Development Team | Jun 18, 2026 - 12:15 | 1.1.27 | 116.65MB | ZIP |  , out of 93 Votes. , out of 93 Votes. |
|
| File Tags | ||||||||
| DocFetcher document-search desktop-search full-text-search indexing search-utility open-source portable-search | ||||||||
Click to Rate File Share it on Twitter → Tweet
|